

2Map Join 连接操作在map端完成mapjoin和reducejoin区别,没有reduce阶段适用于大表与小表连接mapjoin和reducejoin区别,小表数据量能完全加载到内存中缺点是使用范围有限mapjoin和reducejoin区别,只适用于大小表且小表能完全加载到内存中的情况,且小表不能太大,以免消耗内存Map Join在连接时将小表全部读入内存,在map阶段进行匹配,即使出现笛卡尔积,也不会对。
第三种是SemiJoin,它在ReduceJoin的基础上进行优化,通过在map阶段过滤掉一些数据,减少网络传输量2Hive内部表与外部表的主要区别在于内部表在建表时会在HDFS上创建存储目录,增加分区时会将数据复制到指定目录,删除数据时会同时删除表的数据和元数据而外部表通常建立分区,增加分区时不会移动数。
第三,SemiJoin,这是一种对reduceJoin的变体,在map端过滤数据,减少了shuffle网络传输量,实现方式是将小表中参与Join的键单独抽取,通过DistributeCache分发到相关节点,在map阶段扫描连接表,过滤掉join键不在内存哈希集合中的记录,让参与Join的记录通过shuffle传输到reduce端进行Join,与reduceJoin的实现。
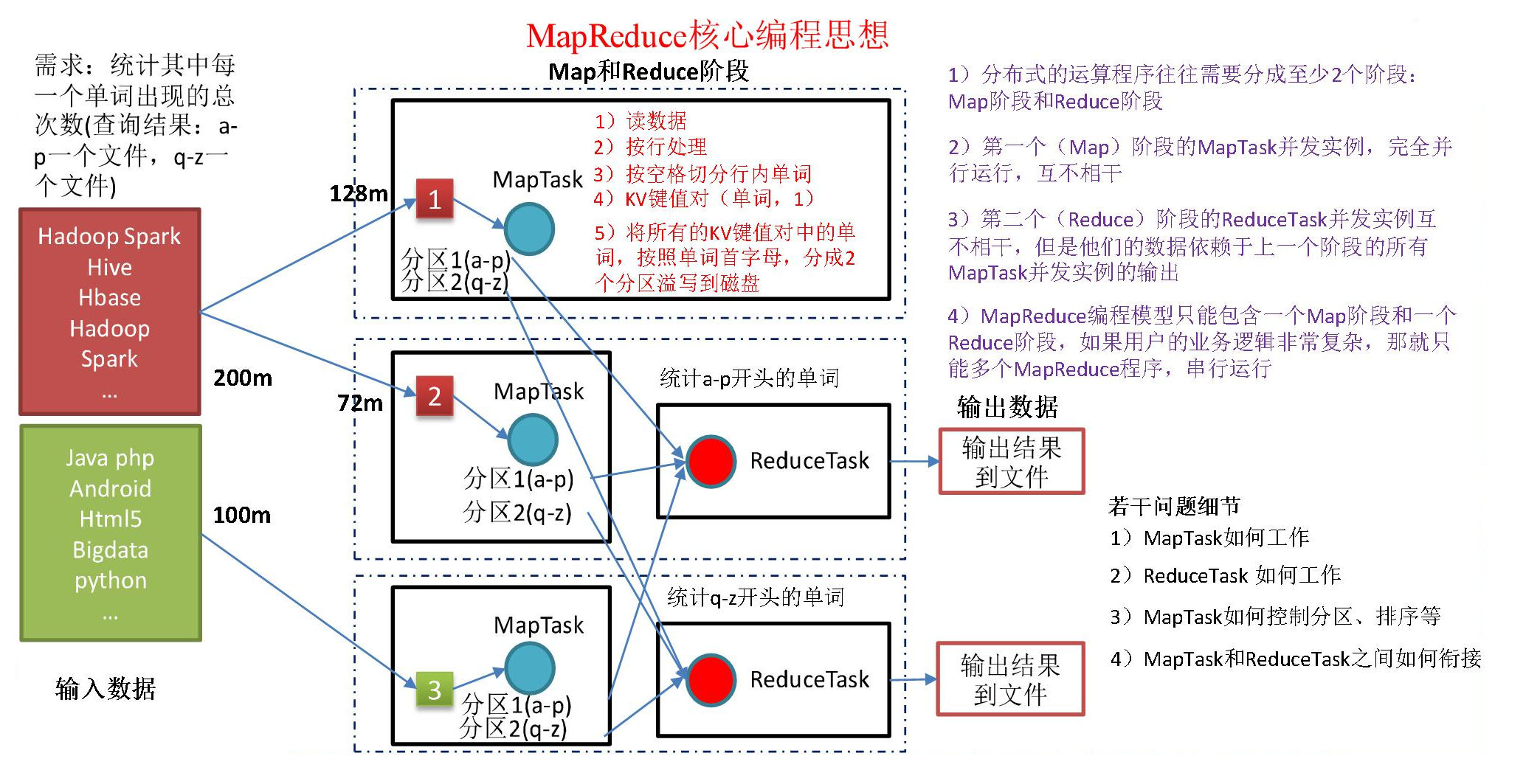
MapReduce中的Join方法主要有以下几种Reduce Side JoinMap阶段对两个输入文件的数据进行处理,并为每条数据添加一个标签,用于区分数据来源于哪个文件例如,tag=0表示数据来自File1,tag=2表示数据来自File2Reduce阶段根据key对数据进行分组,然后对具有相同key但来自不同文件的数据进行连接操作。
2 连接时连接字段列类型不统一Hive默认会尝试转换列类型,若转换失败则会生成null值,与空值造成相同影响,导致倾斜3 大表与小表关联时采用mapjoin方式解决,即将小表作为一个完整的驱动表,在map阶段进行join操作,避免reduce阶段的效率损耗在进行mapjoin时,原理是将小表数据加载至内存中。
在mapjoin过程中,小表作为驱动表,与大表在map阶段进行join操作,通过将数据分布到不同的map中,实现高效的内存级匹配通常情况下,适用于大表与小表关联,且小表可以存放在内存中而不影响性能的情况大表与大表关联时,可以通过设置reduce的字节处理大小,或者设置每个key的倾斜阈值来优化处理设置`。

处理小表与大表的join问题,可以调整参数以自动选择map join,或者设置以适应特定的表大小当表过大时,可以先行进行内关联结果作为小表,或者对小表进行扩容解决大表join时Map输出key数量极少导致reduce端退化为单机作业问题,可以通过对Join表去重。
使用MapJoin需要满足以下条件一份表的数据分布在不同的Map中外,其mapjoin和reducejoin区别他连接的表的数据必须在每个Map中有完整的拷贝在两个要连接的表中,有一个很大,有一个很小,这个小表可以存放在内存中而不影响性能MapJoin是一种在Map阶段进行表之间连接的技术,不需要进入到Reduce阶段才进行连接这样做可以。
1Map设置调整memorysplitsize,根据任务特点合理调整2Join设置调整cpumemory,针对Join任务特性进行调整3Reduce设置调整cpumemory,优化任务性能4小文件合并参数设置。
主要区别在于处理无结构化数据的能力和SQL查询的便捷性Hive的分区和表类型对数据管理和查询效率有显著影响二Hive优化策略 处理数据倾斜数据倾斜是Hive性能优化的一个重要方面,需要通过合理的分区和抽样等技术来缓解合理设置map和reduce任务数量根据数据量和计算资源,合理设置map和reduce任务的数量。








还没有评论,来说两句吧...